新一代通用字符转换环境
用过Unicue或者Ansi2Unicode的童鞋或许会留意到程序目录下有一个叫charmaps的文件夹,没错,里面存放的就是字符映射表了。
1.1版本起,编码转换逻辑已经从程序本身分离,独立发展成为c4-lib(common codes converting context library)。
c4-lib当初的设计目的,可以说是完全达成,用户可以自行制作字符映射表,通过修改字符映射表配置文件,就能够把自定义编码添加进去。(只是目前缺乏说明文档,但通过参考c4-lib的源码,有一定编程功底的童鞋是能够做到的)
最初实现c4-lib后又已经过去了3年,代码逐渐陈腐,思路中的各种不足也暴露了出来。
正是将各种新想法做个总结,推出新一代c4-lib的时候
新一代c4-lib的架构:
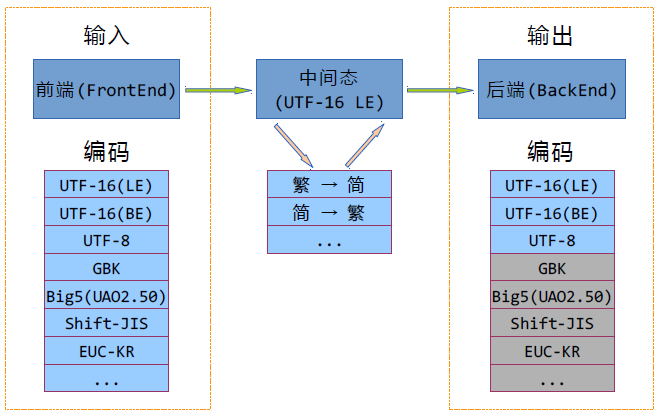
首先,将输入和输出彻底分离,在编码转换过程中,可以抽象出三阶段:前端输入,中间态处理和后端输出。(有点类似编译原理)
中间态的字符编码选用UTF-16小尾序,这决定了前端使用的字符映射表的目标编码只能是UTF-16 LE,后端使用的字符映射表的源编码也只能是UTF-16 LE。也即UTF-16 LE在整个处理流程中担当媒介作用。
前后端各有自己的字符映射表,都是单向表,互不干涉,不像windows的*.nls文件,将两个单向表混合在一起。
那么一个转换规则可以抽象成一个channel(或者叫pipe)。一个channel由一个前端映射表,0个或多个中间态映射表和一个后端映射表构成。这些映射表中,前后端的UTF-16(LE)、UTF-16(BE)、UTF-8为内建,其余的映射表均为外部加载。(很明显UTF-16 LE映射表啥都不用干)
中间态的映射表能干些啥呢?基于Unicode上的简繁转换、中日汉字转换、全半角字符转换、平片假名转换,基本上想得到的都能做得到,还可以多个组合起来使用。一些商业软件在智能搜索方面可能有变态的需求,比如输入平假名,片假名的字符串也能被匹配并高亮,本文的中间态的映射表毫无疑问是可行的解决方案之一。
那么,使用者该如何组装自己的channel呢?
旧版c4-lib的两个charmap:
<charmap>
<name>Shift-JIS</name>
<description>Shift-JIS to Unicode.</description>
<useinautocheck>true</useinautocheck>
<path>charmaps/jis2u-little-endian.map</path>
<feature>BaseOnMultibyte</feature>
<feature>ResultIsUnicode</feature>
<readingpolicy begin="0x00" end="0x7F" readnext="false" />
<readingpolicy begin="0x80" end="0xA0" readnext="true" />
<readingpolicy begin="0xA1" end="0xDF" readnext="false" />
<readingpolicy begin="0xE0" end="0xFF" readnext="true" />
<segment begin="0x0000" end="0x007F" reference="ascii" type="ascii" />
<segment begin="0x0080" end="0x00A0" reference="0xFFFD" type="undefine" />
<segment begin="0x00A1" end="0x00DF" reference="buffer" offset="0" type="JIS-X-0201" />
<segment begin="0x00E0" end="0x813F" reference="0xFFFD" type="undefine" />
<segment begin="0x8140" end="0xFFFF" reference="buffer" offset="63" type="JIS-X-0208" />
</charmap>
<charmap>
<name>Tra-CHN(Unicode) to Simp-CHN(Unicode)</name>
<version>Unicode 4.0 Unihan(Wikipedia version)</version>
<description>Traditional Chinese character to Simplified Chinese character basing on Unicode Plane 0(BMP). Not support character bigger than 0xFFFF.</description>
<useinautocheck>false</useinautocheck>
<path>charmaps/tra2simp-little-endian.map</path>
<feature>BaseOnUnicode</feature>
<feature>ResultIsUnicode</feature>
<readingpolicy begin="0x00" end="0xFF" readnext="true" />
<segment begin="0x0000" end="0x42B6" reference="self" type="Unicode BMP" />
<segment begin="0x42B7" end="0x9F9C" reference="buffer" offset="0" type="Unicode BMP" />
<segment begin="0x9F9D" end="0xFFFF" reference="self" type="Unicode BMP" />
</charmap>
在新一代c4-lib中,charmap作用范围收窄,不再需要也不允许使用诸如
<feature>ResultIsUnicode</feature>
关系到目标或源编码的配置片段,更能体现字符映射的涵义。
charmap的配置如下:
<charmaps>
<charmap>
<name>Shift-JIS (Front-End)</name>
<description>Shift-JIS to Unicode.</description>
<version>Version info here</version>
<type>front-end</type>
<autodetect>true</autodetect>
<path>charmaps/fe-jis2u-little-endian.map</path>
<readingpolicy begin="0x00" end="0x7F" readnext="false" />
<readingpolicy begin="0x80" end="0xA0" readnext="true" />
<readingpolicy begin="0xA1" end="0xDF" readnext="false" />
<readingpolicy begin="0xE0" end="0xFF" readnext="true" />
<segment begin="0x0000" end="0x007F" reference="ascii" type="ascii" />
<segment begin="0x0080" end="0x00A0" reference="0xFFFD" type="undefine" />
<segment begin="0x00A1" end="0x00DF" reference="buffer" offset="0" type="JIS-X-0201" />
<segment begin="0x00E0" end="0x813F" reference="0xFFFD" type="undefine" />
<segment begin="0x8140" end="0xFFFF" reference="buffer" offset="63" type="JIS-X-0208" />
</charmap>
<charmap>
<name>Big5 (Front-End)</name>
<type>front-end</type>
<autodetect>true</autodetect>
<path>charmaps/fe-b2u-little-endian.map</path>
<readingpolicy begin="0x00" end="0x7F" readnext="false" />
<readingpolicy begin="0x80" end="0xFF" readnext="true" />
<segment begin="0x0000" end="0x007F" reference="ascii" type="ascii" />
<segment begin="0x0080" end="0x813F" reference="0xFFFD" type="undefine" />
<segment begin="0x8140" end="0xFFFF" reference="buffer" offset="0" type="big5-multiple-char" />
</charmap>
<charmap>
<name>Tra-CHN(Unicode) to Simp-CHN(Unicode)</name>
<version>Unicode 4.0 Unihan(Wikipedia version)</version>
<description>Traditional Chinese character to Simplified Chinese character basing on Unicode Plane 0(BMP). Not support character bigger than 0xFFFF.</description>
<path>charmaps/mm-tra2simp-little-endian.map</path>
<type>medium-mapping</type>
<segment begin="0x0000" end="0x42B6" reference="self" type="Unicode BMP" />
<segment begin="0x42B7" end="0x9F9C" reference="buffer" offset="0" type="Unicode BMP" />
<segment begin="0x9F9D" end="0xFFFF" reference="self" type="Unicode BMP" />
</charmap>
<charmap>
<name>Shift-JIS (Back-End)</name>
<description>Unicode to Shift-JIS.</description>
<version>Version info here</version>
<type>back-end</type>
<path>charmaps/be-u2jis.map</path>
<segment begin="0x0000" end="0x007F" reference="ascii" type="ascii" />
<segment begin="0x...." end="0x...." reference="buffer" type="JIS-X-0201/0208"/>
<segment begin="0x...." end="0x...." reference="0x0020" type="undefine"/>
</charmap>
<charmap>
<name>Big5 (Back-End)</name>
<description>Unicode to Big5(UAO2.50).</description>
<type>back-end</type>
<path>charmaps/be-u2big5.map</path>
<segment begin="0x0000" end="0x007F" reference="ascii" type="ascii" />
<segment begin="0x...." end="0x...." reference="buffer" type="big5-multiple-char"/>
<segment begin="0x...." end="0x...." reference="0x0020" type="undefine"/>
</charmap>
<charmaps>
其中readingpolicy和autodetect将是前端映射表独有的,因为中间态和后端映射表无需readingpolicy,而自动检测编码方面,也只有前端有这个需求。
channel的配置如下:
<channels>
<channel>
<name>Big5 to UTF-16(LE)</name>
<front-end>Big5 (Front-End)</front-end>
<medium-mappings></medium-mappings>
<back-end>UTF-16(LE)</back-end>
</channel>
<channel>
<name>Big5 to GBK via traditional-to-Simplified</name>
<front-end>Big5 (Front-End)</front-end>
<medium-mappings>
<medium-mapping>Tra-CHN(Unicode) to Simp-CHN(Unicode)</medium-mapping>
</medium-mappings>
<back-end>GBK (Back-End)</back-end>
</channel>
<channel>
<name>UTF-16(LE) to UTF-8</name>
<front-end>UTF-16(LE)</front-end>
<medium-mappings></medium-mappings>
<back-end>UTF-8</back-end>
</channel>
</channels>
可以看到,一个前端(有且只有),0个或n个中间态,一个后端(有且只有),可以组合出千变万化的channel,满足用户的变态需求。
需要补充一点的是,后端的非Unicode多字节编码映射表(GBK/Big5/Shift-JIS/EUC-KR等)的转换是有损的!极不推荐使用这些后端保存转换结果。一旦后端Big5映射表使用UAO2.50版本,保存得到的Big5文本的某些字符有可能在别人电脑上无法识别,导致和Unicode补完计划一样的字符丢失问题。




请教一下 lz , 怎么才能100% 正确的检测一段 字节 是 shift-Jis 还是 GBK。?
即使是人手动辨析,100%的目标也是不现实的,因为Shift-JIS和GBK的码表空间存在重叠部分。当然,针对机器识别,词频分析可以提高准确率,再深入一点还可以做语义分析。要达到100%,枉论这个目标是否能达成,机器识别的准确率肯定要超过人工识别,这个模型谁能建出来?或者寄托希望于人工智能?
噢,明白了,感谢回答!
熏大,应该是用CC4Context类吧?
1.构造
2.init()
3.getMostPossibleEncode() 检测编码
4.getEncode() 输出编码
这样用就好了?
MAP不知道怎么搞,还有什么要注意的?
主要用两个类,CC4Context和CC4Encode
CC4Context::getMostPossibleEncode会返回一个CC4Encode常指针,参数是需要检测的字符串
CC4Context::getEncode同样会返回一个CC4Encode常指针,参数是编码的名字
CC4Encode提供一系列转换函数,你想用的应该会是这两个:
std::wstring virtual wconvertText(const char *src, unsigned int src_length)
std::wstring virtual wconvertString(const char *src)
映射表的制作:
制作不算复杂,将某编码对应的Unicode字符按原来顺序写入二进制文件,不存在的字符则映射到Unicode的0xFFFD。映射表物理文件中的字元是允许不连续的
编写映射表的配置则复杂一点,可以参考Shift-JIS的配置片段(目前c4-lib中最复杂的编码就是Shift-JIS了)。segment的reference目前有四种,ascii/0xFFFD/buffer/self。ascii指的就是ASCII区间了,落在这个区间的字符在转换时直接转换成Unicode中的ASCII码,不查表。0xFFFD是指这个区间没定义,在转换时直接使用0xFFFD填充,也不查表。self是指转换前后编码值没发生变化,主要出现在简繁转换中,也不查表。buffer是指需要查表的区间,必须指定在映射表物理文件中的起始偏移量(offset)。
源码在:http://code.google.com/p/c4-lib/source/browse/trunk/
含有使用例子和映射表制作例子
感谢熏大~准备捣鼓一下转码的东西。
GB18030真心脑残。c4-lib的readpolicy必须修改才能把GB18030作为前端来输入,映射表就更凶残了,一部分必须查表,一部分却又可以通过算法转换,怎么有这么奇葩的设计。简单上来说,0x0000-0xFFFF的Unicode字符(BMP字符),有相当一部分在GBK中没有定义,这部分字符虽然是两字节,但映射到了4字节的GB18030上去了,而且是无规律。前端的映射表制作还罢了,如果要将GB18030作为后端输出,0x0000-0xFFFF的Unicode字符,一会映射到2字节GB18030,一会映射到4字节GB18030,你要是不将2字节对齐到4字节,没法通过偏移量快速查找,对齐嘛,浪费大量空间(映射表文件大小达到256KB)。我朝就是喜欢搞这些没人支持的标准,Unicode都出来了,还弄GB18030干嘛,既然是个全映射,映射规则还乱七八糟,弄出来又有什么用呢?都是处理字符,用Unicode处理难道就会死了?又没见呆丸11区将Big5、Shift-JIS扩展成4字节编码以覆盖所有Unicode字符?