本站域名更换为kuyur.net
忍了.info域名很多年了,更新费用一年比一年贵。
因此更换到.net域名。
以上。
有时候需要同步两个git代码库,而这两个代码库并不是简单的fork关系。手动执行太烦人了,写了一个自动脚本。
#! /bin/sh
WORKSPACE=sync-git-workspace
SOURCE_GIT_REPO=https://github.com/account_source/source_repo_name.git
SOURCE_BRANCH=master
TARGET_GIT_REPO=https://github.com/account_target/target_repo_name.git
TARGET_BRANCH=master
TARGET_GIT_COMMIT_USERNAME=account_target
TARGET_GIT_COMMIT_EMAIL=account_target@example.com
TARGET_GIT_REPO_USERNAME=account_target
TARGET_GIT_REPO_PASSWORD=********
SYNC_SOURCE_FOLDER=.
SYNC_TARGET_FOLDER=.
SOURCE_FOLDER=`echo ${SOURCE_GIT_REPO%.git} | rev | cut -d'/' -f 1 | rev`
TARGET_FOLDER=`echo ${TARGET_GIT_REPO%.git} | rev | cut -d'/' -f 1 | rev`
TARGET_GIT_REPO_WITH_AUTH=`echo $TARGET_GIT_REPO | sed 's/https:\/\//https:\/\/'$TARGET_GIT_REPO_USERNAME':'$TARGET_GIT_REPO_PASSWORD'@''/'`
cd ~
if [ ! -d "$WORKSPACE" ]; then
mkdir $WORKSPACE
fi
cd $WORKSPACE
if [ ! -d "$SOURCE_FOLDER" ]; then
git clone $SOURCE_GIT_REPO
fi
if [ ! -d "$TARGET_FOLDER" ]; then
git clone $TARGET_GIT_REPO
fi
cd $SOURCE_FOLDER
git reset HEAD --hard && git checkout $SOURCE_BRANCH
git remote update && git pull origin
cd ../$TARGET_FOLDER
git reset HEAD --hard && git checkout $TARGET_BRANCH
git remote update && git pull origin
rsync -av --progress ../$SOURCE_FOLDER/$SYNC_SOURCE_FOLDER ./$SYNC_TARGET_FOLDER --exclude .git
if [ "`git diff`" = "" ]; then
echo "Nothing to synchronize. No file is changed."
exit 0
fi
git add --all
git config user.email $TARGET_GIT_COMMIT_EMAIL
git config user.name $TARGET_GIT_COMMIT_USERNAME
git config push.default simple
git commit -m "Synchronize the source code."
git push --repo=$TARGET_GIT_REPO_WITH_AUTH
echo "Source code is synchronized."
exit 0
存在差分的时候会自动commit,并push到远程分支。
需要设置一下如下变量
SOURCE_GIT_REPO : 源代码库 SOURCE_BRANCH : 需要同步的分支(源代码库) TARGET_GIT_REPO : 目标代码库 TARGET_BRANCH : 需要同步的分支(目标代码库) TARGET_GIT_COMMIT_USERNAME : commit时候的author名,这个是可以随意设定的 TARGET_GIT_COMMIT_EMAIL : commit时候的email,其实也是可以随意设定的 TARGET_GIT_REPO_USERNAME : Github的账户,必须是短账户名,不能使用邮件地址 TARGET_GIT_REPO_PASSWORD : Github账户的密码 SYNC_SOURCE_FOLDER : 用于同步的源目录,. 为(源代码库的)根目录 SYNC_TARGET_FOLDER : 用于同步的目标目录,. 为(目标代码库的)根目录
在设定SYNC_SOURCE_FOLDER和SYNC_TARGET_FOLDER后,允许只同步部分目录。
比如将源代码库的所有文件同步到目标代码库的abc目录下:
SYNC_SOURCE_FOLDER=. SYNC_TARGET_FOLDER=abc
保存为sync-git.sh,开跑:
chmod +x sync-git.sh ./sync-git.sh
设定为定时任务:crontab -e
每四小时运行一次脚本:
0 */4 * * * /home/ubuntu/sync-git.sh
上一篇文章谈到蒙特卡洛方法计算圆周率,其中产生高质量随机数的代码:
var arr = crypto.getRandomValues(new Uint32Array(1)); var x = arr[0] / 0xFFFFFFFF; x.toString(2); // 32位循环一次,因此熵仍然是32bit
按照随机数的规范,随机数的区间应该是[0, 1),因此有必要校正为:
var arr = crypto.getRandomValues(new Uint32Array(1)); var x = arr[0] / (0xFFFFFFFF + 1); x.toString(2);
然而,上述方法产生的[0,1)之间的随机浮点数实质上只有32比特的熵,并不能视为一个足够精度的浮点数,也即这些小数不可能分布在一些间隙中。
这是因为将[0,1]区间等分为0xFFFFFFFF + 1份,而随机数只是落在等分点上。
那么如何让这些产生的随机数的间隙更加细腻呢?
1.双精度浮点数规范
根据双精度浮点数的规范,双精度浮点数使用64比特来储存,第1比特是符号位,第2至第12比特是2的指数(exponent),在实际运算时需要减掉0x3ff,第13至第64比特是尾数(mantissa)。
除了0和无穷大这几个特例之外,浮点数的实际值是: (符号位) 2^(exponent – 0x3ff) * (1.mantissa)。
尾数(mantissa)部分共有52比特,如果用bit0~bit51表示其52比特,那么在转换为小数时的公式是 bit0 * 2^(-1) + bit1 * 2^(-2) + bit2 * 2^(-3) + … + bit51 * 2^(-52)。
下文的讨论不考虑符号位。下文中,exponent指存储的数值,而指数部分为实际值,也即exponent – 0x3ff。
浮点数如果要大于等于1,exponent显然要大于等于0x3ff。exponent的最大值是:(111 1111 1111)2进制,也即0x7FF,0x7FF在双精度浮点数中特别定义为无限大。
如果忽略尾数部分,只靠指数部分,那么浮点数能够表达的最大整数是2^(0x7FE – 0x3ff) = 2^1023。如果在浏览器的控制台中,输入Math.pow(2, 1023)和Math.pow(2, 1024)会明显看到这一分界点。
Math.pow(2, 1023); // 8.98846567431158e+307 Math.pow(2, 1024); // Infinity
虽然2^1023是如此之巨大,但实际上由于精度限制,2^1022到2^1023之间的整数无法全部精确表达。
实际上,2^1022下一个能够被表达的整数是2^1022 * (1 + 2^(-52)),也即2^1022 + 2^970。
2.连续整数的最大值
这里有一个很有趣的问题:双精度浮点数能够精确表达的连续整数的最大值是多少?
在研究这个问题之前,首先看整数100是如何在浮点数中编码的。
我们知道,100 > 64 = 2^6 且 100 < 128 = 2^7,那么exponent是:6 + 0x3ff = 0x6 + 0x3ff = 0x405 。
尾数部分 (100 – 2^6) / 2^6 = 36 / 2^6 = 32 / 2^6 + 4 / 2^6 = 2^(-1) + 2^(-4) = 0.5625。
用52bit来编码的话,就是:0x9 0000 0000 0000。
和符号位以及exponent合并起来,整个64bit是:0x4059 0000 0000 0000
这里有个在线的浮点数比特位查看器:http://www.binaryconvert.com/convert_double.html
因此虽然100落在64到128之间,但由于尾数部分的调整,所以仍然能够精确表达。
那么100的下一个浮点数是多少呢?
我们知道100是2^6 * (1 + 2^(-1) + 2^(-4)),那么下一个浮点数就是2^6 * (1 + 2^(-1) + 2^(-4) + 2^(-52)),它们之间的差值是2^6 * 2^(-52) = 2^(-46)。
所以随着指数部分的增加,尾数部分能够微调的最小步进越来越小。也就是说精度随着数的增大而下降。
所以当尾数部分能够精确微调的最小步进大于1时,就是双精度浮点数能够精确表达的连续整数的终点。
当指数部分为52时,尾数部分的最小步进为1 = 2^52 * 2^(-52)。
指数部分为52时的最大整数为:2^52 * (1 + 2^(-1) + 2^(-2) + 2^(-3) + … + 2^(-52)),下一个整数是2^53。这就是连续整数的终点。
所以在浏览器的控制台中,看到这种现象就不神奇了(在指数部分为53时,尾数能够调整的最小步进是2)
Math.pow(2, 53); // 9007199254740992 var i = 9007199254740993; i; // 9007199254740992 i = 9007199254740994; i; // 9007199254740994 i = 9007199254740995; i; // 9007199254740994 i = 9007199254740996; i; // 9007199254740996
3.随机数小数部分的精度
回到随机数问题。我们产生的随机数的目标区间是[0, 1)。然而在[0, 1)之间,双精度浮点数并没有那么简单。
由于双精度浮点数的小数部分的精度表达跟指数部分密切相关。当指数小于1时,指数部分对精度有加成作用。
其实很简单,在[0.5, 1)区间,能够精确表达的浮点数有2^52个,它们在区间内是等距的,而在[0.25, 0.5)区间,浮点数也有2^52个,它们在区间内也是等距的。对于[0.125, 0.25)等等等区间也是如此。因此随着浮点数变小,步进也越来越小。
如果我们使用52随机比特产生[1, 2)区间的随机数,很显然指数部分恒为0,尾数部分的步进是2^(-52),双精度浮点数完全能够精确表达这范围的随机数。
如果使用52随机比特, 记为bit0~bit52,按公式:bit0 * 2^(-1) + bit1 * 2^(-2) + bit2 * 2^(-3) + … + bit51 * 2^(-52)得到的随机数,这些随机数最小值0, 最大值2^(-1) + 2^(-2) + 2^(-3) + … + 2^(-52),也即二进制0.1111111111111111111111111111111111111111111111111111 (=0.9999999999999998),符合在[0, 1)区间均匀分布。那么这些纯小数是否能完全被双精度浮点数表达?这关系到随机数的均匀性是否会因精度的损失而被变形。
答案是,[0, 1)区间以 2^(-52)为步进的纯小数能够完全被双精度浮点数表达。
比如非0的最小的小数,(二进制)0.0000000000000000000000000000000000000000000000000001,也即2^(-52),它的双精度浮点数很容易就计算出为0x3CB0000000000000。(0x3CB – 0x3FF = -52)。这远远没有达到双精度浮点数的能力下限。双精度浮点数的exponent,最小值可以取到0x001,指数为0x001 – 0x3FF = -1022,也即最小的浮点数为2^(-1022)。
最大的小数,(二进制)0.1111111111111111111111111111111111111111111111111111,bit0为1,也即2^(-1)的系数为1,这系数可以放进指数部分里。那么 2^(-1) + bit1 * 2^(-2) + bit2 * 2^(-3) + … + bit51 * 2^(-52) = 2^(-1) * ( 1 + bit1 * 2^(-1) + bit2 * 2^(-2) + … + bit51 * 2^(-51)),稍微复习一下双精度浮点数的规范,很显然指数部分为-1, 尾数部分为1111111111111111111111111111111111111111111111111111 (51位),补齐到52位,也即11111111111111111111111111111111111111111111111111110。 写成hex,那就是0x3FEFFFFFFFFFFFFE。这个过程叫约化。
因此无论是从哪一bit开始为非0值,它都能约化到指数部分,而指数部分的下限值为-52,不可能超过双精度浮点数的-1022下限。而剩余的比特的位数只能少于52位,约化后实际是左移位后作为尾数部分。尾数部分不足52位,在后面补齐0。
4. 52bit精度的蒙特卡洛法计算圆周率
经过上述讨论,按照浮点数的规范,随机数理论上间隙可以小至2^(-52),精度将比2^(-32)得到极大提高。
为了产生52bit的精度,我们需要利用两个Uint32,第一个整数左移20位,第二个整数右移12位(舍弃12位),然后两数相加,得到52比特的随机整数(双精度浮点数形式)。因为第一个整数的左移20位运算已经超出32位整数范围,不能够再使用移位运算符。简单地,乘以2^20即可。52比特的随机整数,除以2^52,等到[0, 1)区间的纯小数,即为我们所需。
function getRandomFloat() {
var arr = crypto.getRandomValues(new Uint32Array(2));
var mantissa = arr[0] * 1048576 + (arr[1] >>> 12);
return mantissa * Math.pow(2,-52);
}
var m = 0, n = 10000;
for (var i = 0; i < n; ++i) {
var x = getRandomFloat();
var y = getRandomFloat();
if (x * x + y * y <= 1) {
m++;
}
}
var pi = 4 * m / n;
console.log(pi);
蒙特卡洛法很流氓,思路却非常简单,往往暴力又好用。通过大量的随机样本,去估算并逼近得到一个渐近值,虽然永远不是确切值,但工程上有一定精度的结果就已经可以接受。
最近连续击败李世石的Google围棋AI AlphaGo,在估算围棋的势的时候,正是使用蒙特卡罗方法。对于一个棋面,要判断黑白子谁的势强,随机轮流落子,最后谁赢就是谁的势强,一盘下来得到的结论虽然比较扯,但大量样本得到的结果却非常有说服力。
那么如何用蒙特卡洛法计算圆周率pi呢?
在1X1的正方形上,以任意一顶点为圆心,1为半径画圆,被正方形的边截出1/4圆弧,其围成的扇形面积是(pi*r^2)/4,因为r=1,所以面积是pi/4。
取其顶点为原点,两边为x,y轴正方向,建立正交直角坐标系。在正方形内取大量随机点为样本,随机点落在扇形内的期望是扇形和正方形的面积之比,即pi/4比1,也即pi/4。
记总样本数为n, 落在扇形内的样本数为m, 当n趋向正无穷时,有m/n=pi/4。那么当n趋向无穷时,pi=4*m/n。
编程实现的话,
var m = 0, n = 10000;
for (var i = 0; i < n; ++i) {
var x = Math.random();
var y = Math.random();
if (x * x + y * y <= 1) {
m++;
}
}
var pi = 4 * m / n;
console.log(pi);
在n=10000时,得到的pi大体在3.13到3.15之间浮动。
然而,在加大样本量到5000000,得到的结果也并不理想,小数点第三位后仍然不稳定,5000000的样本量也只是得到小数点后两位精度。
问题出在哪里?蒙特卡罗法事实上对样本的平均性要求很高。也即随机样本要真的均匀分布在指定范围内,而不是看起来好像是平均分布了。
具体到实现上,就是随机数的生成质量(均匀性)要非常好。
而反过来来说,上面的代码可以测试一个随机数生成算法的质量。
JavaScript的Math.random()得到的随机数是伪随机数,质量差强人意。
相信熟悉Linux的人都知道Linux上最先实现了真随机数生成器 (https://zh.wikipedia.org/wiki//dev/random)。
这是采集自硬件的热噪声并汇聚到系统熵池,根据熵产生的真随机数。当熵耗尽,取随机数便会被阻塞。这意味着,如果不采用专门的真随机数硬件,真随机数是稀少和高时间成本的。(大规模的熵收集可以通过采集大气噪声,这里有一家很有趣的公司:random.org)
折中方案是,利用真随机数作为种子,高质量伪随机数算法生成随机数序列。这种随机数既带有一定程度的熵,又能高效率产生,适合弱安全性场合。新一代浏览器中的crypto模块产生的随机数正是这种思路。
https://developer.mozilla.org/en-US/docs/Web/API/RandomSource/getRandomValues
我们再来计算一下圆周率
var m = 0, n = 10000;
for (var i = 0; i < n; ++i) {
var arr = crypto.getRandomValues(new Uint32Array(2));
var x = arr[0] / 0xFFFFFFFF;
var y = arr[1] / 0xFFFFFFFF;
if (x * x + y * y <= 1) {
m++;
}
}
var pi = 4 * m / n;
console.log(pi);
同样是5000000的样本,crypto.getRandomValues产生的随机数得到的精度可以达到小数点后4位,质量有了一定提高。
毫无疑问,AlphaGo内部肯定有一个高质量的随机数生成器,而且很可能是硬件生成器。
Ripple restful API并不需要实名认证,拿来做客户端再也合适不过了。
* 不用再忍受RippleTrade的乌龟速度 (交易高峰期半天挂不上单浏览器卡死是常有事)
* 无需实名认证
* 迁移Gatehub什么鬼滚蛋去吧
于是就有了ripple-commander,一个基于nodejs的命令行客户端。
https://github.com/kuyur/ripple-commander
https://www.npmjs.com/package/ripple-commander
1.下载并安装nodejs
2.下载ripple-commander源码。
– 使用Git:
git clone https://github.com/kuyur/ripple-commander.git
– 没有安装Git可以下载zip包:https://github.com/kuyur/ripple-commander/archive/master.zip
– Github如果被墙,可以使用npm安装:
npm install ripple-commander
3. 下载必要依赖库 (npm安装方式无需此步)
cd ripple-commander npm install
4. 运行。首次运行会提示输入帐号(ripple地址,不是RippleTrade上的用户名哦)和密钥(secret,不是RippleTrade上的用户密码哦),并自动保存至wallet.txt。
node start-commander.js
1. 随机创建一个钱包 (此方式是从ripple rest api获取的钱包,并非离线钱包)
new-wallet
2. 获取账户余额
get-balance
3. 获取信任链
get-trustlines
4. 添加或移除信任链。将limit设为0即可移除
grant-trustline <issuer> <currency> <limit> [ --allow-rippling ]
5. 转账。例如:send rscxz5PqRrmUaMigyb1mP32To1rQDygxAq 5+XRP
send <destination> <amount+currency+issuer> [ --source-tag=<source_tag> ] [ --destination-tag=<destination_tag> ] [ --invoice-id=<invoice_id> ]
6. 提现!支持自动网桥!例如:send-to-bridge zfb@ripplefox.com 100
send-to-bridge <destination> <amount>
7. 获取一条转账明细
get-payment <resource_id>
8. 获取最近的转账明细
get-payments
9. 获取全部订单
get-orders
10. 挂单。type可以是sell或者buy。例如:place-order sell 100+XRP 5+CNY+rKiCet8SdvWxPXnAgYarFUXMh1zCPz432Y
place-order <type> <amount1+currency1+issuer1> <amount2+currency2+issuer2>
11. 撤单
cancel-order <sequence>
12. 显示市场订单,参数limit为订单数量,最小值10,最大值400,默认为10。注意不包含自动桥接产生的订单。
get-orderbook <currency1+issuer1> <currency2+issuer2> [ --limit=<limit> ]
13. 获取交易状态 (交易可以为转账/挂单/设置信任链)
get-transaction <hash>
14. 显示可信任的网关,数据来自https://ripple.com/knowledge_center/gateway-information/。新建并编辑issuers.json可添加自定义网关,具体格式参考issuers.json.sample。
show-issuers [ --keyword=<issuer_name> ]
15. 加密钱包(AES算法),加密后的钱包文件名为wallet.dat
encrypt-wallet
16. 解密钱包
decrypt-wallet
17. 显示钱包里的所有账户
show-accounts [ --show-secret ]
18. 添加一个账户
add-account [ <address> ]
19. 切换当前使用的账户
change-account [ <address> ]
20. 从钱包删除账户
remove-account [ <address> ]
命令行语法简单说明:
[]内为可选参数。<>内为变量。
未来还将支持:
* 智能自动补完
* 管道 (比如你要对一大批账户发送小额xrp奖励,文件中每一行有地址和数额,使用shell命令可以读出每一行,然后管道输出到ripple-commander,实现批量发送)
英文版说明见readme@github。
欢迎打赏:rscxz5PqRrmUaMigyb1mP32To1rQDygxAq
提醒:
第三方的客户端,如果不能够审查源码是绝对不能用的。闭源的工具离得越远越好。
补充:
windows10以下的命令行窗口不能调整宽度,表格会看起来不对齐。推荐linux平台或者console2.
语义分析太难,但基于常用字/生僻字字频分析的方法应该还是可行的。
因为如果生僻字的出现频率太高,有很高概率文本不是这种编码。
算法1:(基于字频统计宏观数据)(ASCII字符不参与字频统计)
a.基于大数据(新闻/文学/维基词条等)进行统计分析,建立字频表。
b.以字频的倒数作为生僻指数
c.将转换后的文本的全部文字的生僻指数累加
d.根据生僻指数累加值给出字符编码判断
缺点1:对于专业文档(比如故意含有某个生僻字的语言学论文),有可能由于生僻字的超高指数导致判断失败
改进方法:b步骤中,建立更加科学的生僻指数,将单个生僻字的影响因子降低。比如开方/取对数(最常用字指数为0, 最不常用字指数为20)
缺点2:对文本内容的自然语言和编码脱节的文件的判断很可能不正确。比如以BIG5编码的日文音乐CUE文件。
因为基于繁体中文自然语言建立的字频表,假名和日文汉字的出现频率较低
改进方法1:针对所有可能编码进行转换,然后对所有自然语言进行分析。缺点:耗时。优点:不但可以给出可能的原始编码,还可以给出自然语言判断。
改进方法2:不再区分自然语言,对东亚语言的所有字符建立统一字频表。一种方法是,取100W字简体中文文章,100W字日文文章,100W字繁体中文文章,100W字韩文文章,先分别统计在各自然语言中的字频,取最高者合并到单一字频表中(这个合并后的字频表基于Unicode)
缺点:对于少量文字的文本,判断可能仍然不准确。Shift-JIS的假名字符,按照EUC-KR编码转换,有可能落在谚文文字区。而假名字符和谚文字符都是高频字符。
算法2:(基于字频分布相似度)(ASCII字符不参与字频统计)
a.基于字频,将字符按常用度分级。比如分成20级。建立字频映射表 (比如 “的” -> 0级)
b.生成字符常用度分布参考曲线
c.统计转换后文本在每级中的字符数量,生成统计曲线
d.计算c中的统计曲线和b中的参考曲线的相似度 (约化后计算方差)
优点:不但可以给出编码,还可以给出自然语言的判断。(方差值小者相似度高)
缺点:依赖文本的文字量。东亚语言的字频分布曲线可能都很相似。如0级字符,占文本80%(随便乱猜的数据哦)。
判断过程的例子:
以EUC-KR编码的日文音乐CUE文件:
1.筛选出候选编码,排除不可能编码。假设候选编码只剩下BIG5和EUC-KR。
2.按照BIG5编码转换,得到转换文本。执行算法2,给出各自然语言的相似度
3.按照EUC-KR编码进行转换,得到转换文本。执行算法2,给出各自然语言的相似度
4.取2和3中相似度最高者。
5.相似度最高者对应的编码为可能编码
算法3:(云计算)
对于只含少量文字的文本,可以用Google进行检索,返回词条数目少者,则很可能不是正确编码
在公司内曾经用英文写过一篇关于JavaScript的原型以及继承机制的启蒙文章。
有空的话余用中文重写一次。
I will talk something about prototype and inheritance of JavaScript in this article.
If a class is alone, a.k.a, it has no superclass nor subclass, and such instances will be very few in memory, it is OK to define private members in javascript-closure.
Let’s call it “closure-style”.
foo = function() {
/** private member */
var _colors = []; // array is poor performance, just for example
this.addColor = function(color) {
if (!this.hasColor(color)) {
_colors.push(color);
}
};
this.hasColor = function(color) {
return goog.array.contains(_colors, color);
};
this.removeColor = function(color) {
var index = goog.array.indexOf(_colors, color);
if (index >= 0) {
goog.array.removeAt(_colors, index);
}
};
};
var f1 = new foo();
var f2 = new foo();
f1.addColor === f2.addColor; // false
var arr = [];
var timestamp = new Date;
for (var i = 0; i < 100000; ++i) {
arr[i] = new foo();
}
console.log(new Date - timestamp);
Functions are also instances, but they are not shared when we use “closure-style”.
That is why prototype is recommended. We can share the functions between instances constructed with same constructor.
We use annotation to mark the private members, and the advanced compiler such as Google Closure Compiler, is able to check if the rule has been broken or not.
foo = function() {
/**
* @private
* @type {Array}
*/
this.colors_ = []; // array is poor performance, just for example
};
foo.prototype.addColor = function(color) {
if (!this.hasColor(color)) {
this.colors_.push(color);
}
};
foo.prototype.hasColor = function(color) {
return goog.array.contains(this.colors_, color);
};
foo.prototype.removeColor = function(color) {
var index = goog.array.indexOf(this.colors_, color);
if (index >= 0) {
goog.array.removeAt(this.colors_, index);
}
};
var f1 = new foo();
var f2 = new foo();
f1.addColor === f2.addColor; // true
var arr = [];
var timestamp = new Date;
for (var i = 0; i < 100000; ++i) {
arr[i] = new foo();
}
console.log(new Date - timestamp);
Because public methods have to access private members, private member can not be written in “closure-style”.
Let’s call it “prototype-style”.
Functions on prototype chain will be shared between instances. There is only 1 copy.
When there are thousands of such instances, we can save memory and time by using “prototype-style”.
I most want to talk about inheritance, it is the reason why I suggest to use “prototype-style”.
Consider a new class inherited from ‘foo’:
bar = function() {
// some codes here
};
bar.prototype = new foo();
var b1 = new bar();
var b2 = new bar();
b1.addColor('red');
b2.hasColor('red'); // true
No matter which style (“prototype-style” or “closure-style”) we use, the private member become shared in prototype chain.
All the instances of “bar” will share a same Object as prototype parent, which is an instance of “foo”.
So, not only methods in “foo” are shared, but also private members in “foo” too.
(Another problem is parameters can not be passed to superclass’s constructor.)
The “prototype-style” has a simple solution to fix the problem, when “closure-style” can not be fixed by this solution.
bar = function() {
this.colors_ = [];
};
bar.prototype = new foo();
var b1 = new bar();
var b2 = new bar();
b1.addColor('red');
b2.hasColor('red'); // false
But when the prototype chain is growing, it is so stupid and ugly to define private members of superclasses in constructor again and again.
Google Closure library provides an inheritance solution (Parasitic Combination Inheritance) for us, basing on “prototype-style”.
We can:
1. Reuse constructor of superclass.
2. Share all prototype-chain functions between instances of a class.
3. Member variables of superclass are separated between instances of subclass.
4. Override and reuse prototype-chain functions easily.
5. still use instanceof and isPrototypeOf normally.
6. Earn the high performance brought from ADVANCED OPTIMIZATIONS of Closure Compiler.
bar = function() {
// call constructor of superclass
goog.base(this);
};
goog.inherits(bar, foo);
var b1 = new bar();
var b2 = new bar();
b1.addColor('red');
b2.hasColor('red'); // false
b1.addColor === b2.addColor // true
Override will become very simple:
bar = function() {
// call constructor of superclass
goog.base(this);
/**
* @private
* @type {Object}
*/
this.colormap_ = {};
};
goog.inherits(bar, foo);
/**
* @override
*/
bar.prototype.addColor = function(color) {
if (this.colormap_[color]) {
return;
}
// reuse function
goog.base(this, 'addColor', color);
this.colormap_[color] = true;
};
/**
* @override
*/
bar.prototype.hasColor = function(color) {
return !!this.colormap_[color];
};
/**
* @override
*/
bar.prototype.removeColor = function(color) {
if (!this.hasColor(color)) {
return;
}
// reuse function
goog.base(this, 'removeColor', color);
delete this.colormap_[color];
};
var b1 = new bar();
var b2 = new bar();
b1.addColor('red');
b2.hasColor('red'); // false
b1.addColor === b2.addColor // true
var f1 = new foo();
b1.addColor === f1.addColor // false
b1 instanceof bar; // true
b1 instanceof foo; // true
f1 instanceof bar; // false
f1 instanceof foo; // true
Object.prototype.isPrototypeOf(b1); // true
foo.prototype.isPrototypeOf(b1); // true
bar.prototype.isPrototypeOf(b1); // true
foo.prototype.isPrototypeOf(f1); // true
bar.prototype.isPrototypeOf(f1); // false
The solution from Google Closure Library is suitable for complicated Class architecture, which might be used in a big application holding thousands of Objects in memory.
I don’t know there is a similar mechanism in jQuery or not.
But if you are just using Google Closure Library, please consider about “prototype-style” and google’s solution first.
If you are not using Google Closure Library, but have to design a Complicated Class architecture, and have no idea about Inheritance of JavaScript, I think “prototype-style” will be much suitable, please google “Parasitic Combination Inheritance” and implement one. I think it is not so difficult.
See also:
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Inheritance_and_the_prototype_chain
URL重写(.htaccess)只是将匹配的URL转发出去而已。如果转发出去的URL被GFW封锁,国内的用户就不能访问。余博客的音乐试听,音乐文件存放在onedrive(skydrive)上,虽然onedrive没被封,但获取动态链接是通过部署在GAE上的skydrive-gae,所以这音乐试听一直都是海外专用啊
.htaccess
RewriteEngine On RewriteBase / RewriteRule ^(.*)$ http://your-app-id.appspot.com/cid-xxxxxxxxxxxxxxxx.office.live.com/self.aspx/.Public/$1
不理会skydrive-gae的内部实现,从浏览器的console都能看到两次302跳转,第一次从自己的域名跳到appspot.com,第二次从appspot.com跳到onedrive的动态地址。
然而,既然从appspot.com返回来的不是二进制文件内容而是302跳转,那么通过apache的反向代理(proxy_http)先取得appspot.com返回来的response header,并原封不动再送到浏览器,可一举突破防火墙。同时,由于转送的数据是response header,并不会显著加重apache服务器的负担,也不会大幅消耗服务器的带宽,浏览器看到的跳转降为1次。因此这种场合,更适用反向代理。
如果正在使用较新的ubuntu,启用proxy_http非常简单:
sudo a2enmod proxy_http
打开 /etc/apache2/sites-available/default.conf,按如下添加ProxyRequests, ProxyPass 和 ProxyPassReverse三行:
<VirtualHost *:80>
...
DocumentRoot /var/www
ServerName your.domain.com
ProxyRequests Off
ProxyPass /music/ http://your-app-id.appspot.com/cid-xxxxxxxxxxxxxxxx.office.live.com/self.aspx/.Public/
ProxyPassReverse /music/ http://your-app-id.appspot.com/cid-xxxxxxxxxxxxxxxx.office.live.com/self.aspx/.Public/
...
</VirtualHost>
重启apache服务器反向代理就生效了。
实践证明,即使是onedrive上的图片,也能外链了。
用过Unicue或者Ansi2Unicode的童鞋或许会留意到程序目录下有一个叫charmaps的文件夹,没错,里面存放的就是字符映射表了。
1.1版本起,编码转换逻辑已经从程序本身分离,独立发展成为c4-lib(common codes converting context library)。
c4-lib当初的设计目的,可以说是完全达成,用户可以自行制作字符映射表,通过修改字符映射表配置文件,就能够把自定义编码添加进去。(只是目前缺乏说明文档,但通过参考c4-lib的源码,有一定编程功底的童鞋是能够做到的)
最初实现c4-lib后又已经过去了3年,代码逐渐陈腐,思路中的各种不足也暴露了出来。
正是将各种新想法做个总结,推出新一代c4-lib的时候
新一代c4-lib的架构:
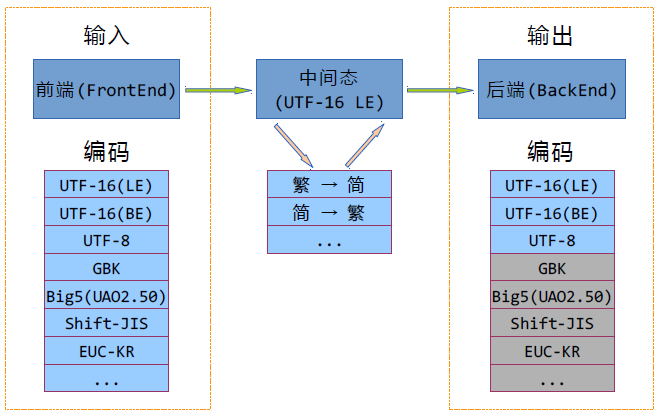
首先,将输入和输出彻底分离,在编码转换过程中,可以抽象出三阶段:前端输入,中间态处理和后端输出。(有点类似编译原理)
中间态的字符编码选用UTF-16小尾序,这决定了前端使用的字符映射表的目标编码只能是UTF-16 LE,后端使用的字符映射表的源编码也只能是UTF-16 LE。也即UTF-16 LE在整个处理流程中担当媒介作用。
前后端各有自己的字符映射表,都是单向表,互不干涉,不像windows的*.nls文件,将两个单向表混合在一起。
那么一个转换规则可以抽象成一个channel(或者叫pipe)。一个channel由一个前端映射表,0个或多个中间态映射表和一个后端映射表构成。这些映射表中,前后端的UTF-16(LE)、UTF-16(BE)、UTF-8为内建,其余的映射表均为外部加载。(很明显UTF-16 LE映射表啥都不用干)
中间态的映射表能干些啥呢?基于Unicode上的简繁转换、中日汉字转换、全半角字符转换、平片假名转换,基本上想得到的都能做得到,还可以多个组合起来使用。一些商业软件在智能搜索方面可能有变态的需求,比如输入平假名,片假名的字符串也能被匹配并高亮,本文的中间态的映射表毫无疑问是可行的解决方案之一。
那么,使用者该如何组装自己的channel呢?
旧版c4-lib的两个charmap:
<charmap>
<name>Shift-JIS</name>
<description>Shift-JIS to Unicode.</description>
<useinautocheck>true</useinautocheck>
<path>charmaps/jis2u-little-endian.map</path>
<feature>BaseOnMultibyte</feature>
<feature>ResultIsUnicode</feature>
<readingpolicy begin="0x00" end="0x7F" readnext="false" />
<readingpolicy begin="0x80" end="0xA0" readnext="true" />
<readingpolicy begin="0xA1" end="0xDF" readnext="false" />
<readingpolicy begin="0xE0" end="0xFF" readnext="true" />
<segment begin="0x0000" end="0x007F" reference="ascii" type="ascii" />
<segment begin="0x0080" end="0x00A0" reference="0xFFFD" type="undefine" />
<segment begin="0x00A1" end="0x00DF" reference="buffer" offset="0" type="JIS-X-0201" />
<segment begin="0x00E0" end="0x813F" reference="0xFFFD" type="undefine" />
<segment begin="0x8140" end="0xFFFF" reference="buffer" offset="63" type="JIS-X-0208" />
</charmap>
<charmap>
<name>Tra-CHN(Unicode) to Simp-CHN(Unicode)</name>
<version>Unicode 4.0 Unihan(Wikipedia version)</version>
<description>Traditional Chinese character to Simplified Chinese character basing on Unicode Plane 0(BMP). Not support character bigger than 0xFFFF.</description>
<useinautocheck>false</useinautocheck>
<path>charmaps/tra2simp-little-endian.map</path>
<feature>BaseOnUnicode</feature>
<feature>ResultIsUnicode</feature>
<readingpolicy begin="0x00" end="0xFF" readnext="true" />
<segment begin="0x0000" end="0x42B6" reference="self" type="Unicode BMP" />
<segment begin="0x42B7" end="0x9F9C" reference="buffer" offset="0" type="Unicode BMP" />
<segment begin="0x9F9D" end="0xFFFF" reference="self" type="Unicode BMP" />
</charmap>
在新一代c4-lib中,charmap作用范围收窄,不再需要也不允许使用诸如
<feature>ResultIsUnicode</feature>
关系到目标或源编码的配置片段,更能体现字符映射的涵义。
charmap的配置如下:
<charmaps>
<charmap>
<name>Shift-JIS (Front-End)</name>
<description>Shift-JIS to Unicode.</description>
<version>Version info here</version>
<type>front-end</type>
<autodetect>true</autodetect>
<path>charmaps/fe-jis2u-little-endian.map</path>
<readingpolicy begin="0x00" end="0x7F" readnext="false" />
<readingpolicy begin="0x80" end="0xA0" readnext="true" />
<readingpolicy begin="0xA1" end="0xDF" readnext="false" />
<readingpolicy begin="0xE0" end="0xFF" readnext="true" />
<segment begin="0x0000" end="0x007F" reference="ascii" type="ascii" />
<segment begin="0x0080" end="0x00A0" reference="0xFFFD" type="undefine" />
<segment begin="0x00A1" end="0x00DF" reference="buffer" offset="0" type="JIS-X-0201" />
<segment begin="0x00E0" end="0x813F" reference="0xFFFD" type="undefine" />
<segment begin="0x8140" end="0xFFFF" reference="buffer" offset="63" type="JIS-X-0208" />
</charmap>
<charmap>
<name>Big5 (Front-End)</name>
<type>front-end</type>
<autodetect>true</autodetect>
<path>charmaps/fe-b2u-little-endian.map</path>
<readingpolicy begin="0x00" end="0x7F" readnext="false" />
<readingpolicy begin="0x80" end="0xFF" readnext="true" />
<segment begin="0x0000" end="0x007F" reference="ascii" type="ascii" />
<segment begin="0x0080" end="0x813F" reference="0xFFFD" type="undefine" />
<segment begin="0x8140" end="0xFFFF" reference="buffer" offset="0" type="big5-multiple-char" />
</charmap>
<charmap>
<name>Tra-CHN(Unicode) to Simp-CHN(Unicode)</name>
<version>Unicode 4.0 Unihan(Wikipedia version)</version>
<description>Traditional Chinese character to Simplified Chinese character basing on Unicode Plane 0(BMP). Not support character bigger than 0xFFFF.</description>
<path>charmaps/mm-tra2simp-little-endian.map</path>
<type>medium-mapping</type>
<segment begin="0x0000" end="0x42B6" reference="self" type="Unicode BMP" />
<segment begin="0x42B7" end="0x9F9C" reference="buffer" offset="0" type="Unicode BMP" />
<segment begin="0x9F9D" end="0xFFFF" reference="self" type="Unicode BMP" />
</charmap>
<charmap>
<name>Shift-JIS (Back-End)</name>
<description>Unicode to Shift-JIS.</description>
<version>Version info here</version>
<type>back-end</type>
<path>charmaps/be-u2jis.map</path>
<segment begin="0x0000" end="0x007F" reference="ascii" type="ascii" />
<segment begin="0x...." end="0x...." reference="buffer" type="JIS-X-0201/0208"/>
<segment begin="0x...." end="0x...." reference="0x0020" type="undefine"/>
</charmap>
<charmap>
<name>Big5 (Back-End)</name>
<description>Unicode to Big5(UAO2.50).</description>
<type>back-end</type>
<path>charmaps/be-u2big5.map</path>
<segment begin="0x0000" end="0x007F" reference="ascii" type="ascii" />
<segment begin="0x...." end="0x...." reference="buffer" type="big5-multiple-char"/>
<segment begin="0x...." end="0x...." reference="0x0020" type="undefine"/>
</charmap>
<charmaps>
其中readingpolicy和autodetect将是前端映射表独有的,因为中间态和后端映射表无需readingpolicy,而自动检测编码方面,也只有前端有这个需求。
channel的配置如下:
<channels>
<channel>
<name>Big5 to UTF-16(LE)</name>
<front-end>Big5 (Front-End)</front-end>
<medium-mappings></medium-mappings>
<back-end>UTF-16(LE)</back-end>
</channel>
<channel>
<name>Big5 to GBK via traditional-to-Simplified</name>
<front-end>Big5 (Front-End)</front-end>
<medium-mappings>
<medium-mapping>Tra-CHN(Unicode) to Simp-CHN(Unicode)</medium-mapping>
</medium-mappings>
<back-end>GBK (Back-End)</back-end>
</channel>
<channel>
<name>UTF-16(LE) to UTF-8</name>
<front-end>UTF-16(LE)</front-end>
<medium-mappings></medium-mappings>
<back-end>UTF-8</back-end>
</channel>
</channels>
可以看到,一个前端(有且只有),0个或n个中间态,一个后端(有且只有),可以组合出千变万化的channel,满足用户的变态需求。
需要补充一点的是,后端的非Unicode多字节编码映射表(GBK/Big5/Shift-JIS/EUC-KR等)的转换是有损的!极不推荐使用这些后端保存转换结果。一旦后端Big5映射表使用UAO2.50版本,保存得到的Big5文本的某些字符有可能在别人电脑上无法识别,导致和Unicode补完计划一样的字符丢失问题。

评论